


 #ClickHouse just discovered that being #lazy is lucrative and they're throwing a #party to celebrate—because who doesn’t want to attend a #conference for a product that's too lazy to load its own data?
#ClickHouse just discovered that being #lazy is lucrative and they're throwing a #party to celebrate—because who doesn’t want to attend a #conference for a product that's too lazy to load its own data?  Apparently, they’re also offering a "Bring Your Own Cloud" feature, so you can experience the thrill of paying for something you already own!
Apparently, they’re also offering a "Bring Your Own Cloud" feature, so you can experience the thrill of paying for something you already own! 
https://clickhouse.com/blog/clickhouse-gets-lazier-and-faster-introducing-lazy-materialization #BYO #Cloud #Data #Celebration #HackerNews #ngated

ClickHouseClickHouse gets lazier (and faster): Introducing lazy materializationClickHouse learned to procrastinate strategically. Discover how lazy materialization skips unnecessary column reads to accelerate queries.




 ClickHouse 的 Rust 一年
ClickHouse 的 Rust 一年

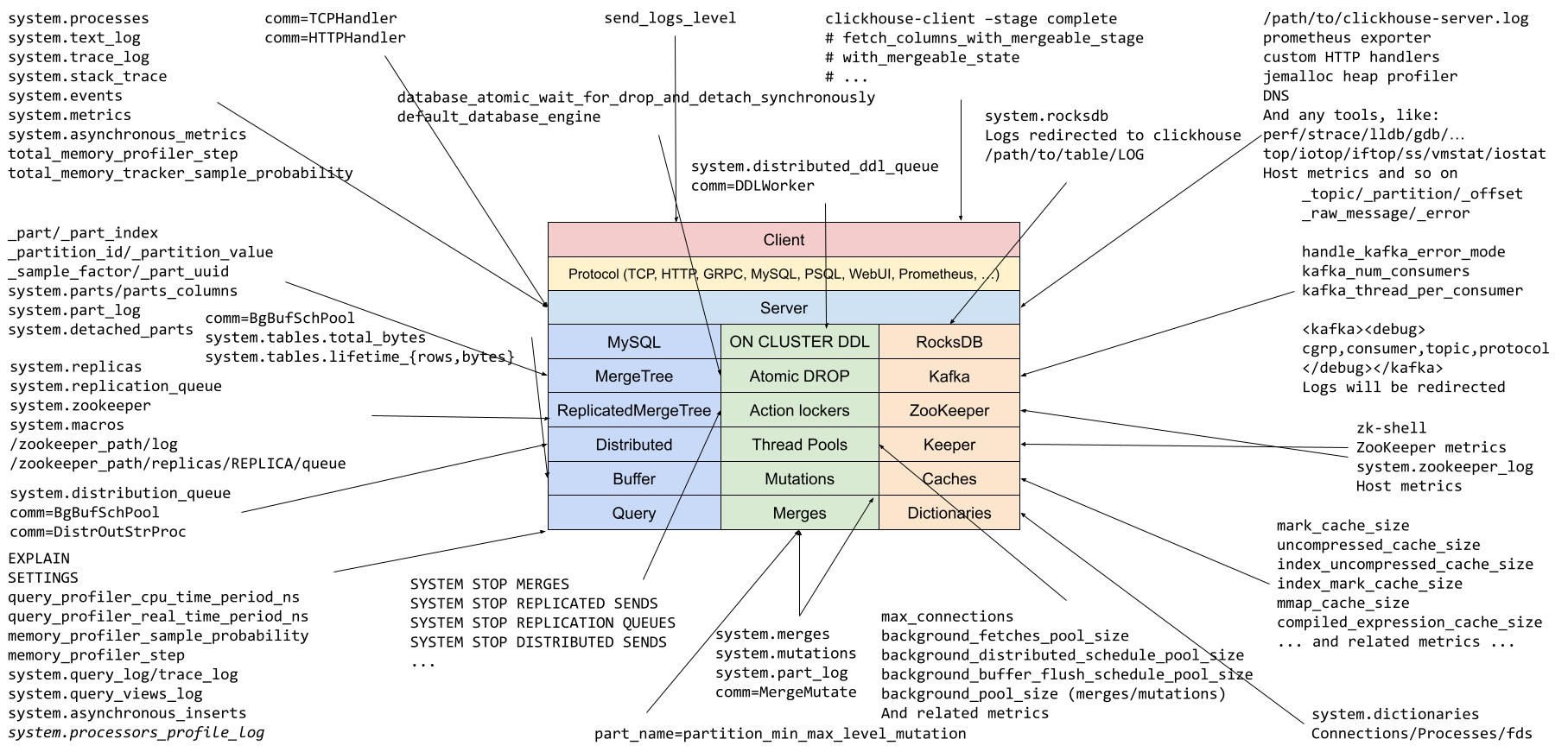



 Click here
Click here 
 So, aspiring
So, aspiring  Meanwhile, the rest of us are still trying to figure out why "collaborate outside of code" sounds like a bad
Meanwhile, the rest of us are still trying to figure out why "collaborate outside of code" sounds like a bad 





 可靠地在PostgreSQL和ClickHouse之間複製數據第一部分 - PeerDB 開源 | BenjaminWootton.com
可靠地在PostgreSQL和ClickHouse之間複製數據第一部分 - PeerDB 開源 | BenjaminWootton.com
